
Fast and Scalable Algorithms for Topic Modeling
Project Summary
Learning meaningful topic models with massive document collections which contain millions of documents and billions of tokens is challenging because of two reasons: First, one needs to deal with a large number of topics (typically in the order of thousands). Second, one needs a scalable and efficient way of distributing the computation across multiple machines. In this project, we aim to develop novel algorithms which tackles both these problems. In order to handle large number of topics we proposed F+LDA, which uses an appropriately modified Fenwick tree. This data structure allows us to sample from a multinomial distribution over T items in O(log T) time. Moreover, when topic counts change the data structure can be updated in O(log T) time. In order to distribute the computation across multiple processor we present a novel asynchronous distributed framework Nomad-LDA. We show that F+Nomad LDA, a combination of F+LDA and Nomad-LDA, significantly outperform state-of-the-art on massive problems which involve millions of documents, billions of words, and thousands of topics.Project Description
Topic models provide a way to aggregate vocabulary from a document corpus to form latent “topics.” In particular, Latent Dirichlet Allocation (LDA) [Blei et al, 2003] is one of the most popular topic modeling approaches. Learning meaningful topic models with massive document collections which contain millions of documents and billions of tokens is challenging because of two reasons: First, one needs to deal with a large number of topics (typically in the order of thousands). Second, one needs a scalable and efficient way of distributing the computation across multiple machines. In this project, we develop a new algorithm F+Nomad LDA which which simultaneously tackles both these problems.
F+LDA: A Fast LDA Sampling Technique.
In this project, we study F+tree, a variant of of the Fenwick tree which allows us to efficiently encode a T-dimensional multinomial distribution using O(T) space. Sampling can be performed in O(log T) time and maintaining the data structure only requires O(log T) work.

Illustration of sampling and updating using F+tree in logarithmic time.
To speedup the traditional collapsed Gibbs sampling (CGS), which costs O(T) time at each step, we propose a fast sampling algorithm F+LDA, where T is the number of topics. F+LDA only costs O(log T) times by utilizing the F+tree data structure and the property that each CGS step only changes two parameters. Empirical results that F+LDA outperforms other state-of-the-art approaches drastically.
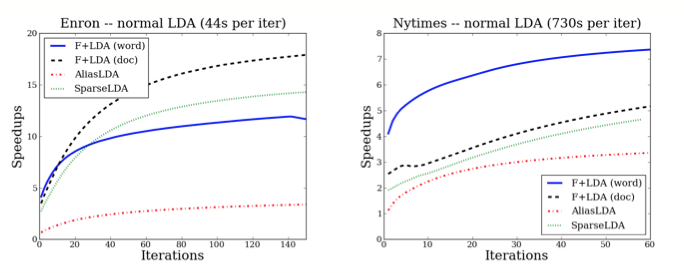
Enron: 38K docs with 6M tokens; Nytimes: 300K docs with 100M tokens. T=1024.
F+NOMAD LDA: A Scalable Distributed Framework for LDA.
We introduce an access graph to analyze the potential parallelism and identify the following key property of various inference methods for topic modeling: only a single vector of size T needs to be synchronized across multiple processors.
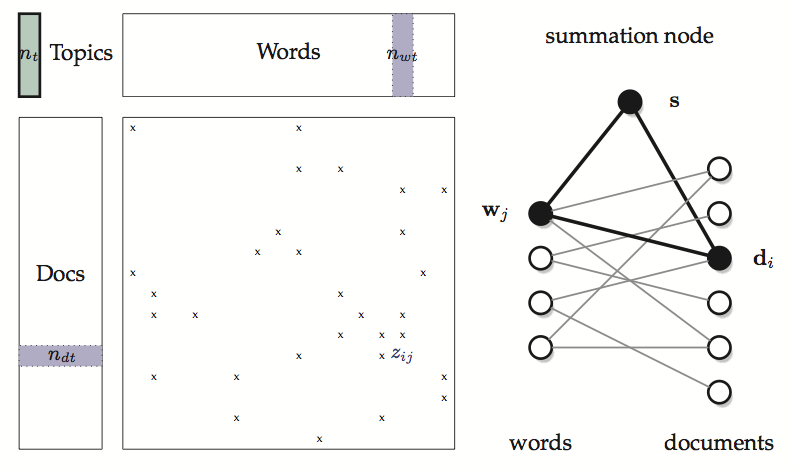
Access Graph of CGS for LDA. Each CGS step is a triangle in the graph.
Based on our analysis, we proposed a novel parallel framework for various types of inference methods for topic modeling. Our framework utilizes the concept of nomadic tokens to avoid locking and conflict at the same time. Our parallel approach is fully asynchronous with non-blocking communication, which leads to good speedups. Moreover, our approach minimizes the staleness of the variables (at most T variables can be stale) for distributed parallel computation.
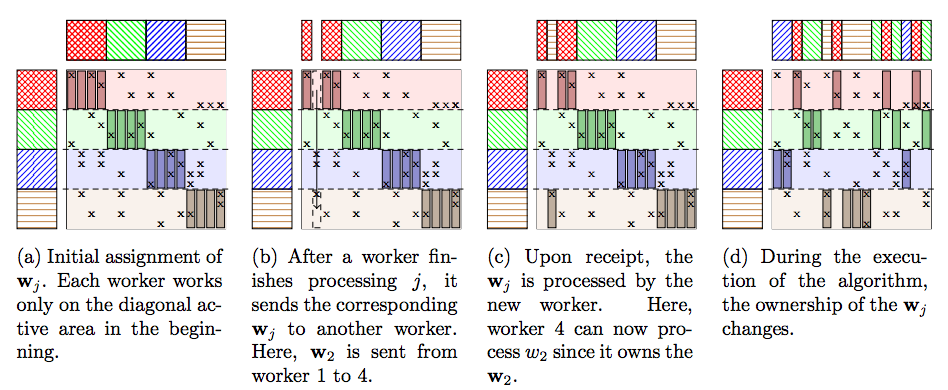
Illustration of the Nomad LDA algorithm
Empirical results on both multi-core and distributed systems, F+Nomad-LDA outperforms other state-of-the-art methods.
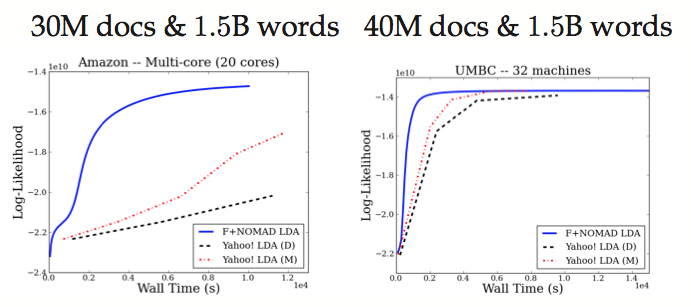
The comparison of F+Nomad-LDA to Yahoo-LDA
Main Publications
- A Scalable Asynchronous Distributed Algorithm for Topic Modeling (pdf, arXiv, software, code)
H. Yu, C. Hsieh, H. Yun, S. Vishwanathan, I. Dhillon.
In International World Wide Web Conference (WWW), pp. 1340-1350, May 2015. (Oral)