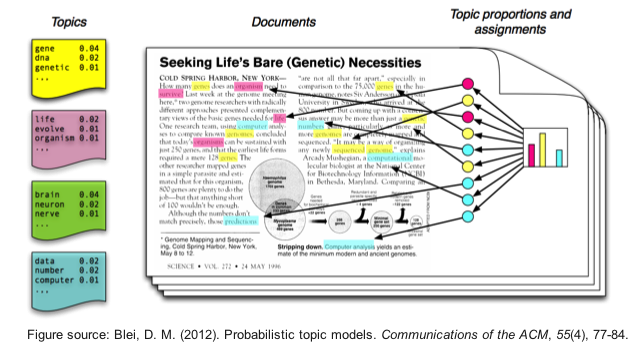
Fast and Scalable Algorithms for Topic Modeling
Learning meaningful topic models with massive document collections which contain millions of documents and billions of tokens is challenging because of two reasons: First, one needs to deal with a large number of topics (typically in the order of thousands). Second, one needs a scalable and efficient way of distributing the computation across multiple machin…
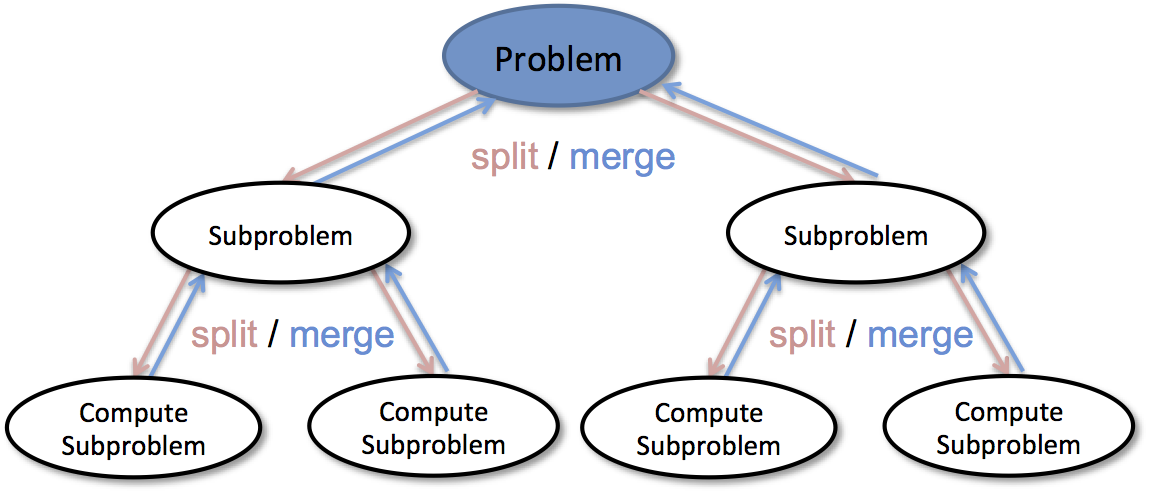
Divide & Conquer Methods for Big Data Analytics
Recently, solving large-scale machine learning problems has become a very important issue. Many of the state-of-the-art approaches for such problems rely on numerical optimization, however, because of the scalability issues, usually one cannot directly apply classical optimization methods to solve large-scale problems. In this project, we apply divide and …
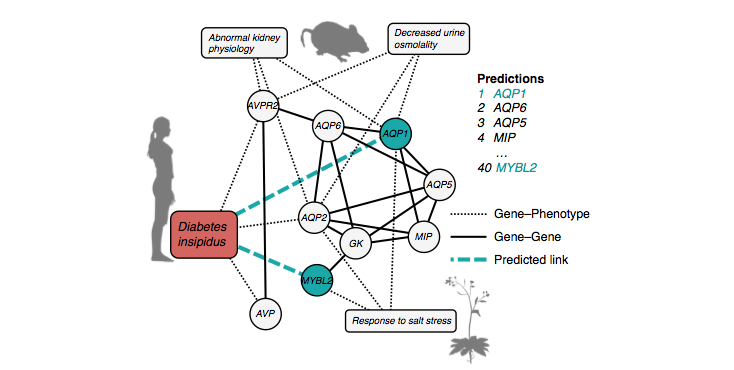
Gene-Disease Prediction: A Link Prediction Approach
We develop methods for predicting gene-disease associations, an important problem in computational biology. The prediction problem can be posed as link prediction in a heterogeneous network consisting of bipartite gene-disease network, gene-interactions network and disease similarity network. In the partially supervised formulation (called positive-unlabel…
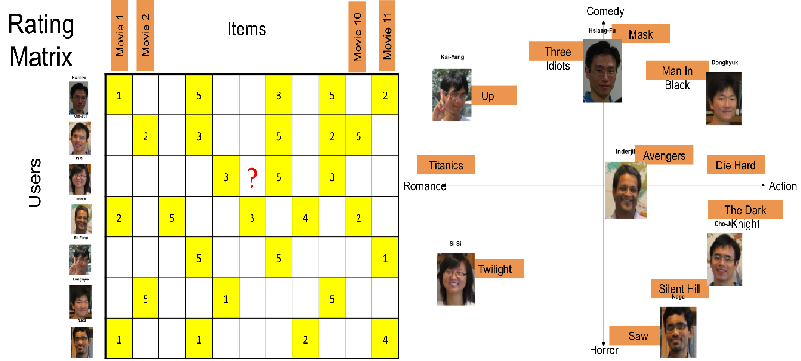
Large-Scale Recommender Systems
Low-rank Matrix factorization in the presence of missing values has become one of the popular techniques to estimate dyadic interaction between entities in many applications such as the friendship prediction in social networks (e.g., Facebook) and the preference estimation in recommender systems (e.g., Netflix). Although there are some existing methods …
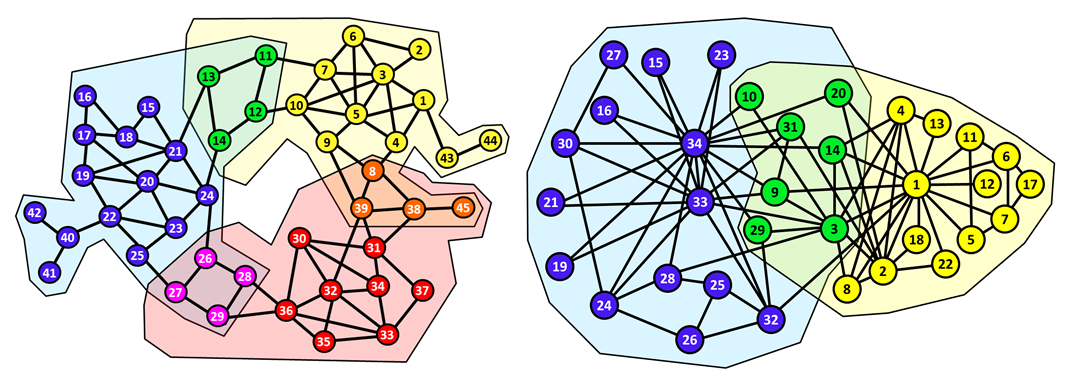
Overlapping Community Detection in Massive Social Networks
Community detection is an important task in network analysis. A community (also referred to as a cluster) is a set of cohesive vertices that have more connections inside the set than outside. In many social and information networks, these communities naturally overlap. For instance, in a social network, each vertex in a graph corresponds to an individual who…
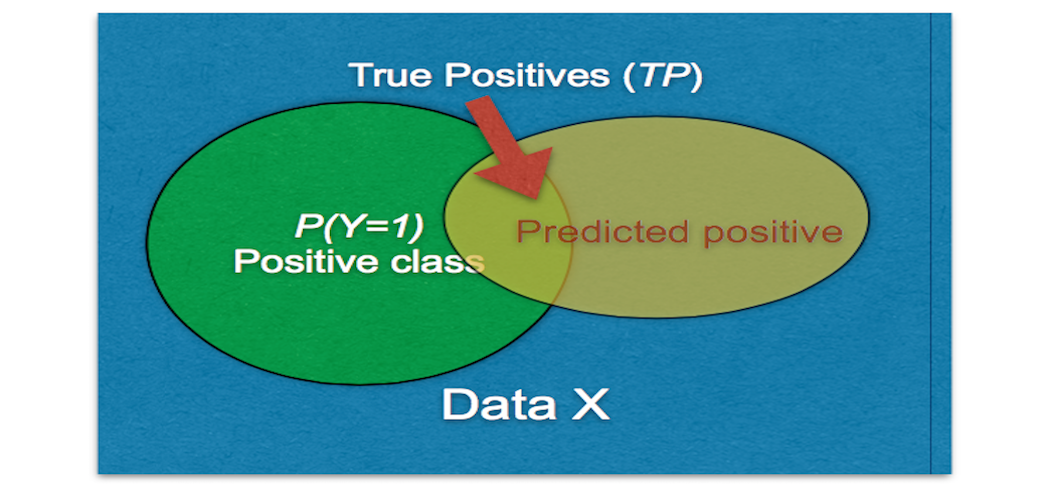
Learning with General Performance Metrics
Traditional machine learning methods such as SVM and logistic regression have become the de facto choices for practitioners, thanks to the availability of scalable, fast, and — importantly — easy-to-use software implementations such as LIBLINEAR. On the theoretical side, advances in learning theory have led to a great deal of understanding in sta…
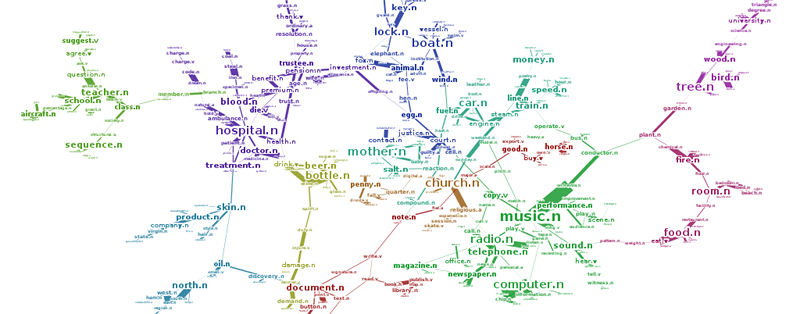
Topic Models with Word Dependencies
Download APM overview slides This project develops a two new topic model based on an Poisson Markov Random Fields (PMRF), which can model dependencies between words. Previous independent topic models such as PLSA (Hofmann, 1999), LDA (Blei, 2003) or SAM (Reisinger, 2010) did not explicitly model dependencies between words. More generally, this proj…
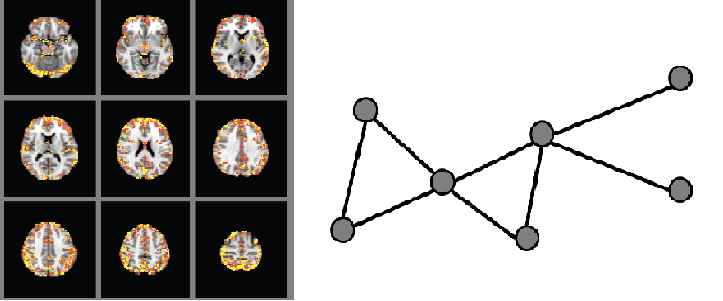
Large Scale Inverse Covariance Estimation
Graphical models have become an important field of machine learning research. In many applications, the structure of graphical models is unknown and has to be learnt from real data. For example, we can recover the gene-gene network from the given micro-array data, or estimate the interactions between different brain regions using the fMRI brain images. Th…
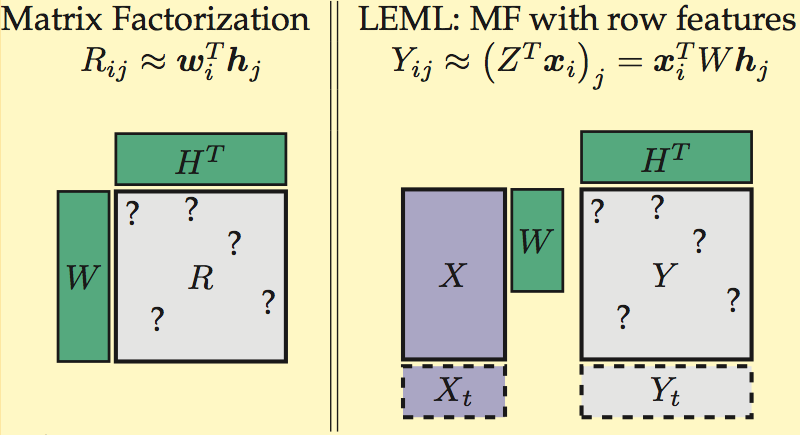
Large-scale Multi-label Learning
Multi-label classification problems abound in practice; as a result, many methods have recently been proposed for these problems. However, there are two key challenges that have not been adequately addressed: (a) the number of labels can be numerous, for example, in the millions, and (b) the test data can be riddled with missing labels. In this project,…

Social Balance Theory for Signed Network Analysis : A Global Approach
The study of social networks is a burgeoning research area. However, most existing work deals with networks that simply encode whether relationships exist or not. In contrast, relationships in signed networks can be positive (“like”, “trust”) or negative (“dislike”, “distrust”). The theory of social balance shows that signed networks tend to …
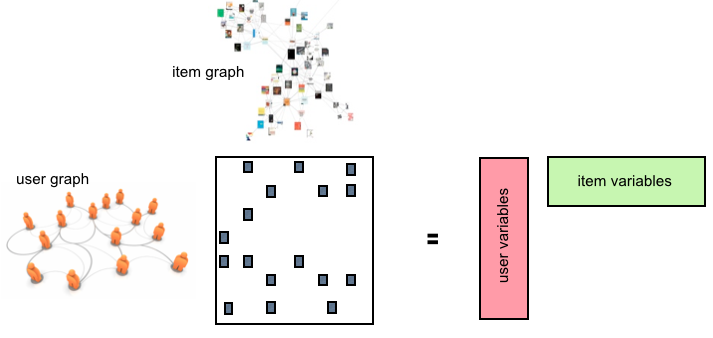
Beyond Low Rank Matrix Factorization
Matrix factorization (MF) approaches are incredibly popular in several machine learning areas, from collaborative filtering to computer vision. While low rank MF methods have been extensively studied both theoretically and algorithmically, often one has additional information about the problem at hand. For example, in recommender systems one might have acces…